
🌟 Visit the Official Project Website & Analyzer
Structured Reasoning aims at enhancing the reasoning capabilities of LLMs from the step level. By treating a reasoning process as a directed acyclic graph, we introduce MaxFlow and LCS algorithms to construct and optimize sparse reasoning graphs, consistently outperforming standard GRPO across varying context lengths with remarkable efficiency and stability.
Abstract
Recent Large Language Models (LLMs) have made remarkable progress, but they still struggle with complex reasoning tasks such as logical deduction and planning. This is partly because they rely primarily on token-level probability relationships, which limits their ability to reason effectively. In this paper, inspired by cognitive science and neurosymbolic AI, we introduce Structured Reasoning, which aims at enhancing the reasoning capabilities of LLMs from the step level.
To this end, we first collect high‑frequency, domain‑agnostic reasoning step tags and construct a structured reasoning dataset with those tags. Then, we treat a reasoning process as a directed acyclic graph, where the vertices represent steps and the edges indicate the direction of reasoning. In this context, an efficient reasoning process corresponds to, or can be characterized by, a sparse reasoning graph.
To construct reasoning graphs, we introduce structured tags for reliable step extraction from LLM outputs.
- Single-graph optimization: We propose the MaxFlow reward, which rewards graphs with balanced node contributions and fewer redundant steps. The quality of a sparse reasoning graph can be reflected by the total flow from all steps to the final answer.
- Multi-graph comparison: We propose the LCS reward, which selects reliable reasoning paths by identifying optimal common subsequences (consecutive steps) shared across multiple generated responses (sequences).
Experiments with DeepSeek-R1-Distill-Qwen-1.5B and 7B models show that our method consistently outperforms GRPO and other carefully tuned baselines across various context lengths (0.5k–8k). Structured Reasoning shows particular strength in efficiency (better performance with fewer steps) and stability (consistently generating high-quality outputs across a temperature range of 0.1 to 1.0).
Methodology
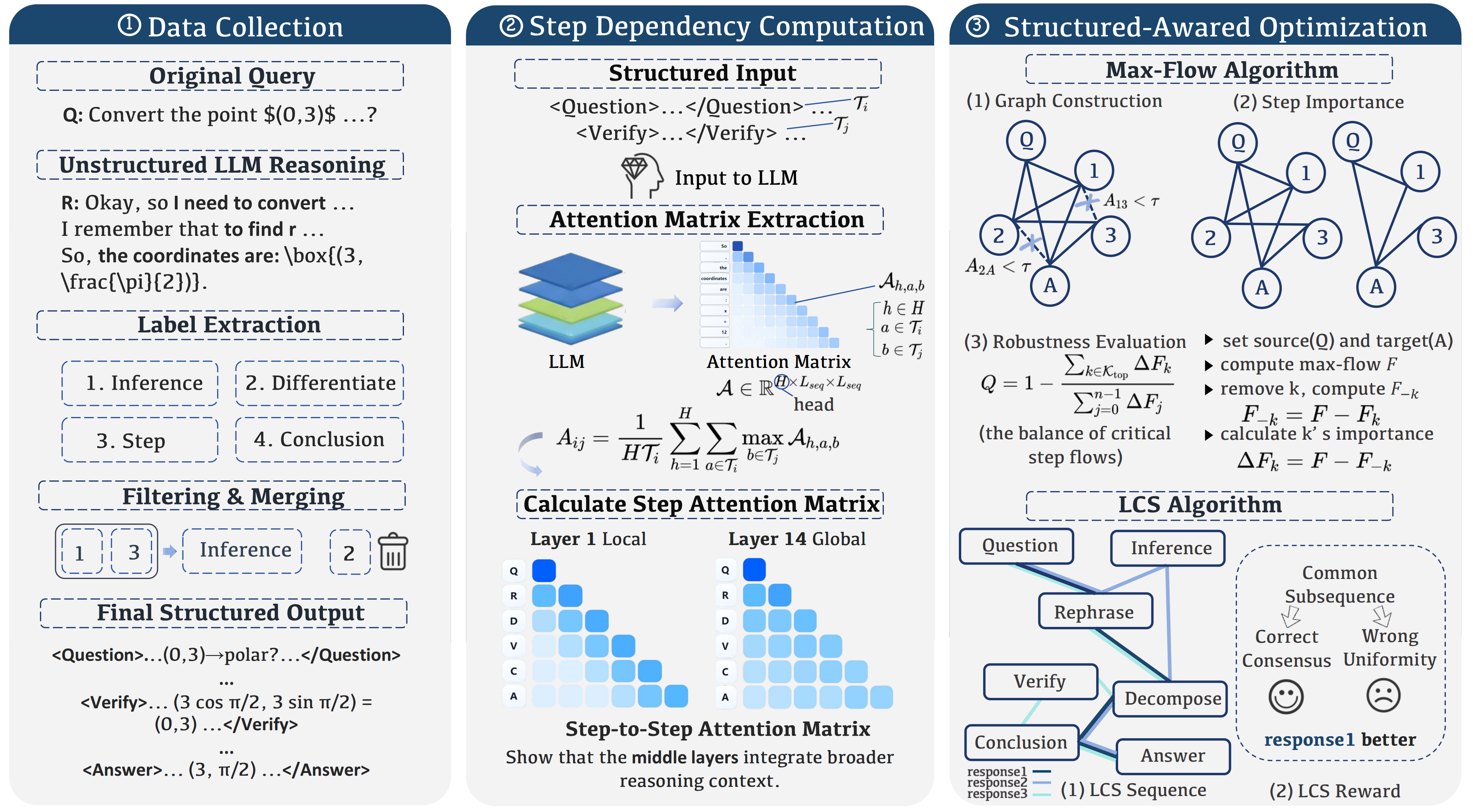
Illustration of our three-stage pipeline for enhancing LLMs with Structured Reasoning:
- Data Collection: Extract structured reasoning labels from unstructured LLM responses, producing outputs with explicit Question, Verify, and Answer components.
- Step Dependency Computation: Compute step-to-step attention matrices to reveal step dependencies and construct directed graphs.
- Structure-Aware Optimization: Apply the Max-Flow algorithm to provide a significantly more accurate understanding of reasoning step dependencies compared to perplexity, and the LCS algorithm to improve reasoning quality by identifying optimal common subsequences across multiple generated responses.
Performance Highlights
1. Efficiency
We evaluate all models across six mathematics-focused benchmark datasets and three out-of-domain datasets (reading, legal, and massive multitask). Our structure-aware optimization methods consistently outperform other baselines for 1.5B models. Notably, MaxFlow with 4k training length achieves significant average improvement over GRPO and surpasses DeepScaleR-1.5B-Preview (trained with maximum 24k length and evaluated with 32k length). For 7B models, the LCS method performs excellently under 4k maximum length, while MaxFlow outperforms by a large margin across the entire length range.
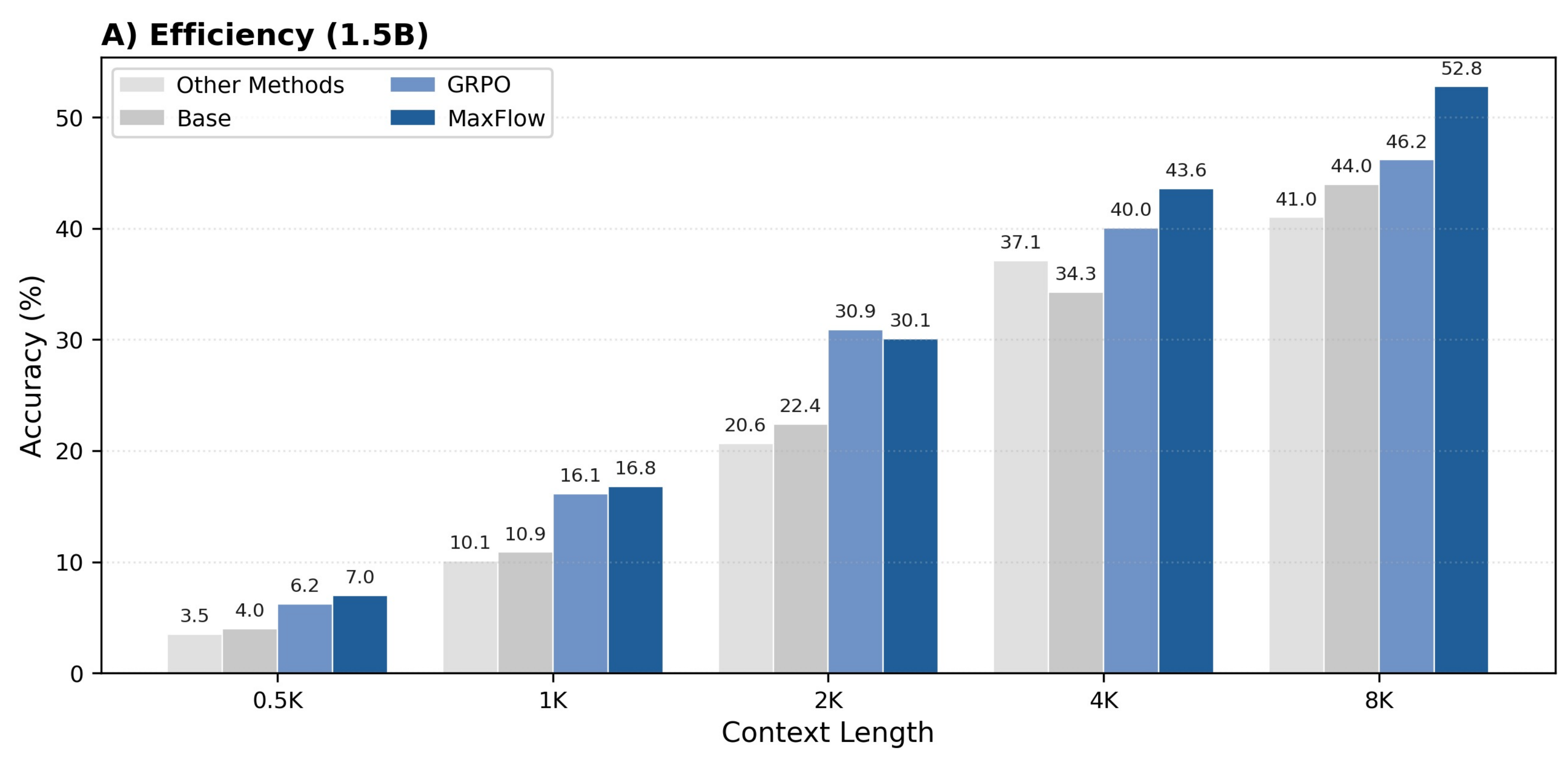
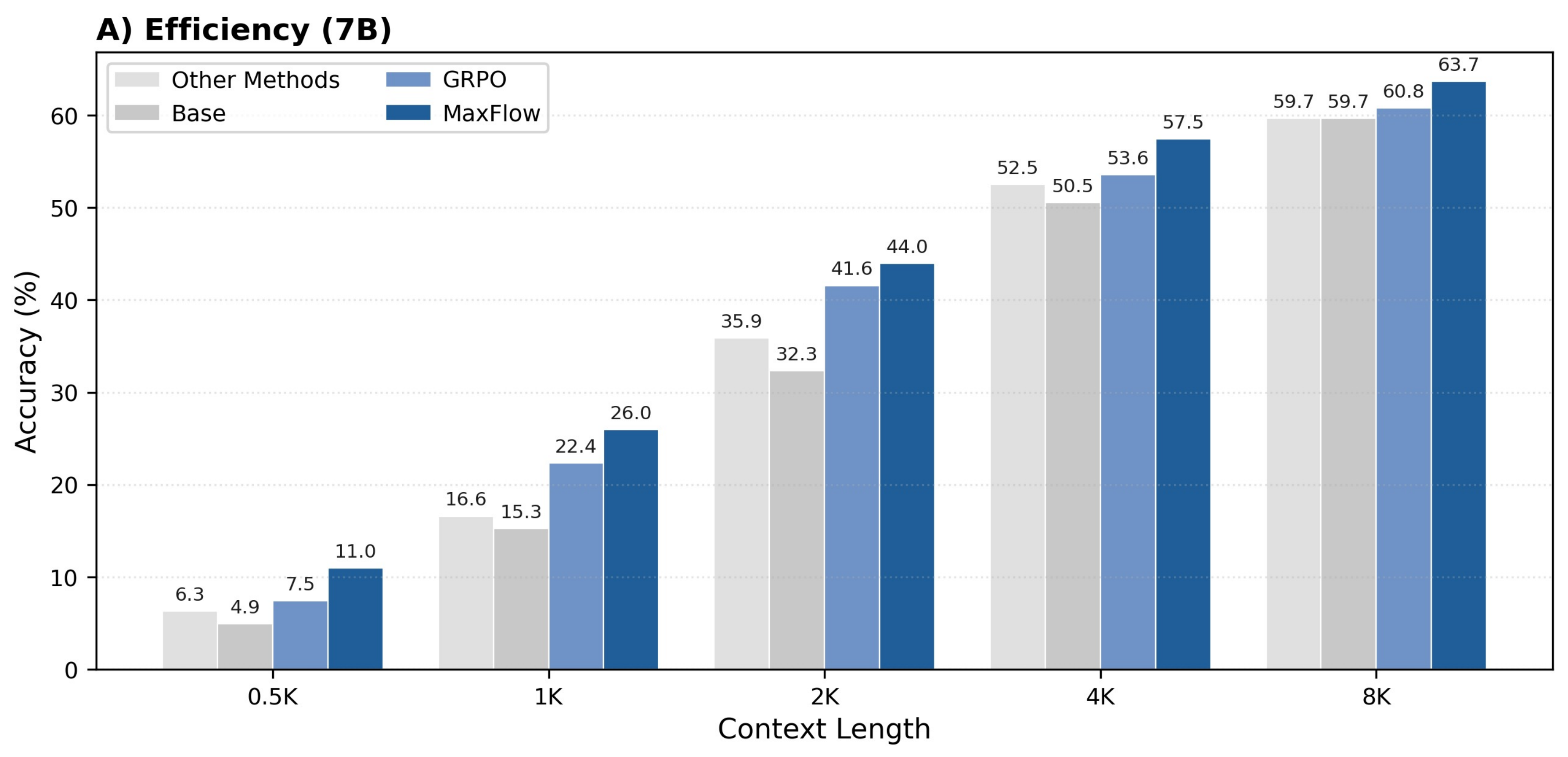
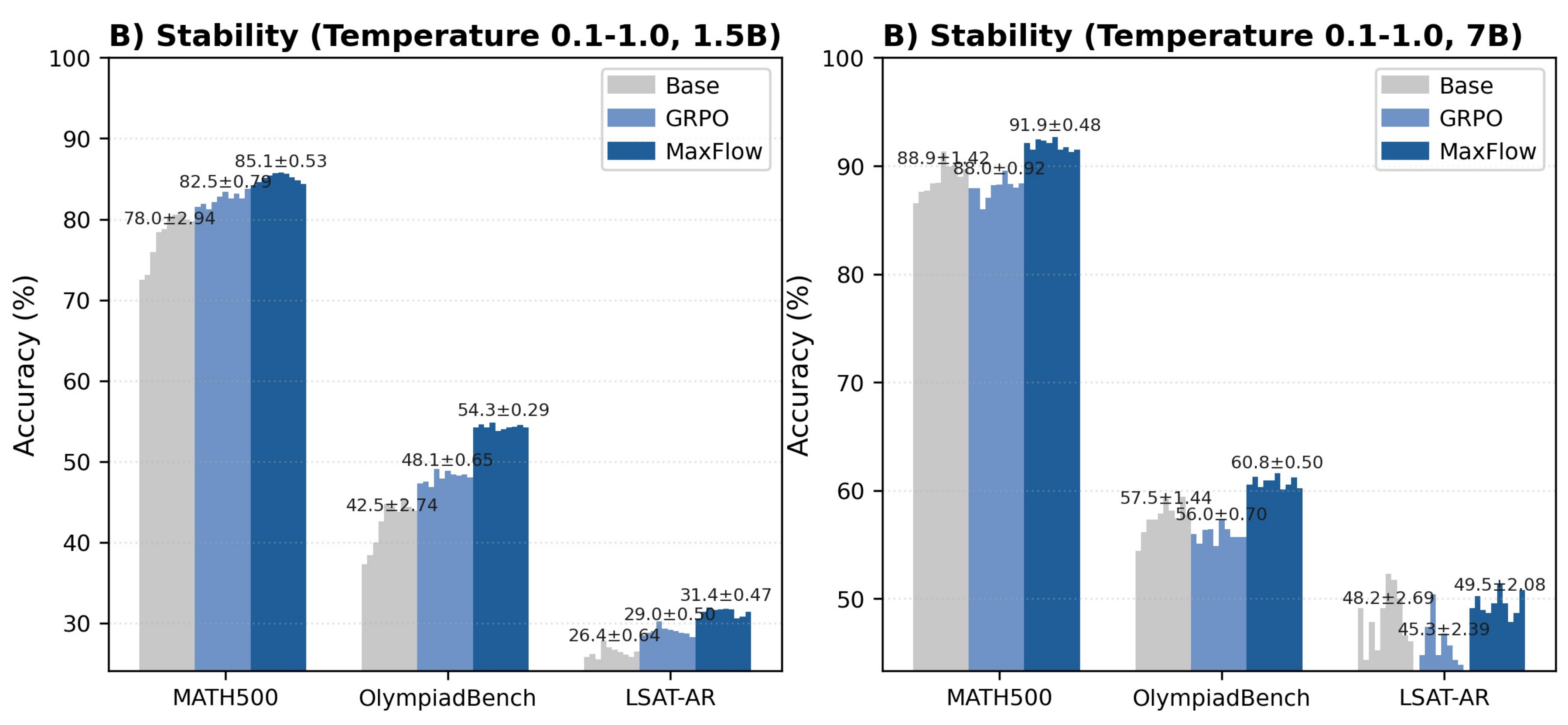
2. Stability
Baseline DeepSeek-R1-Distill models exhibit significant temperature sensitivity, relying heavily on sampling diversity to achieve better performance as temperature increases from 0.1 to 0.9. In contrast, our MaxFlow method maintains consistent performance across all temperature settings, achieving the lowest variance (±0.53 on MATH500 and ±0.29 on OlympiadBench for the 1.5B model). This robustness indicates that structured reasoning frameworks produce inherently stable outputs without requiring specific sampling parameters.
3. Explainability
Through our evaluation, we found that PPL (perplexity) primarily reflects information quantity and cannot distinguish valuable reasoning from disruptive content. Removing steps with the lowest PPL performed similarly to our methods when dealing with redundant but harmless information. However, our proposed methods based on the step-matrix (top-k, top-p, and max-flow) significantly outperformed PPL-based approaches and random removal, verifying that step-matrix-based methods better identify critical reasoning steps.
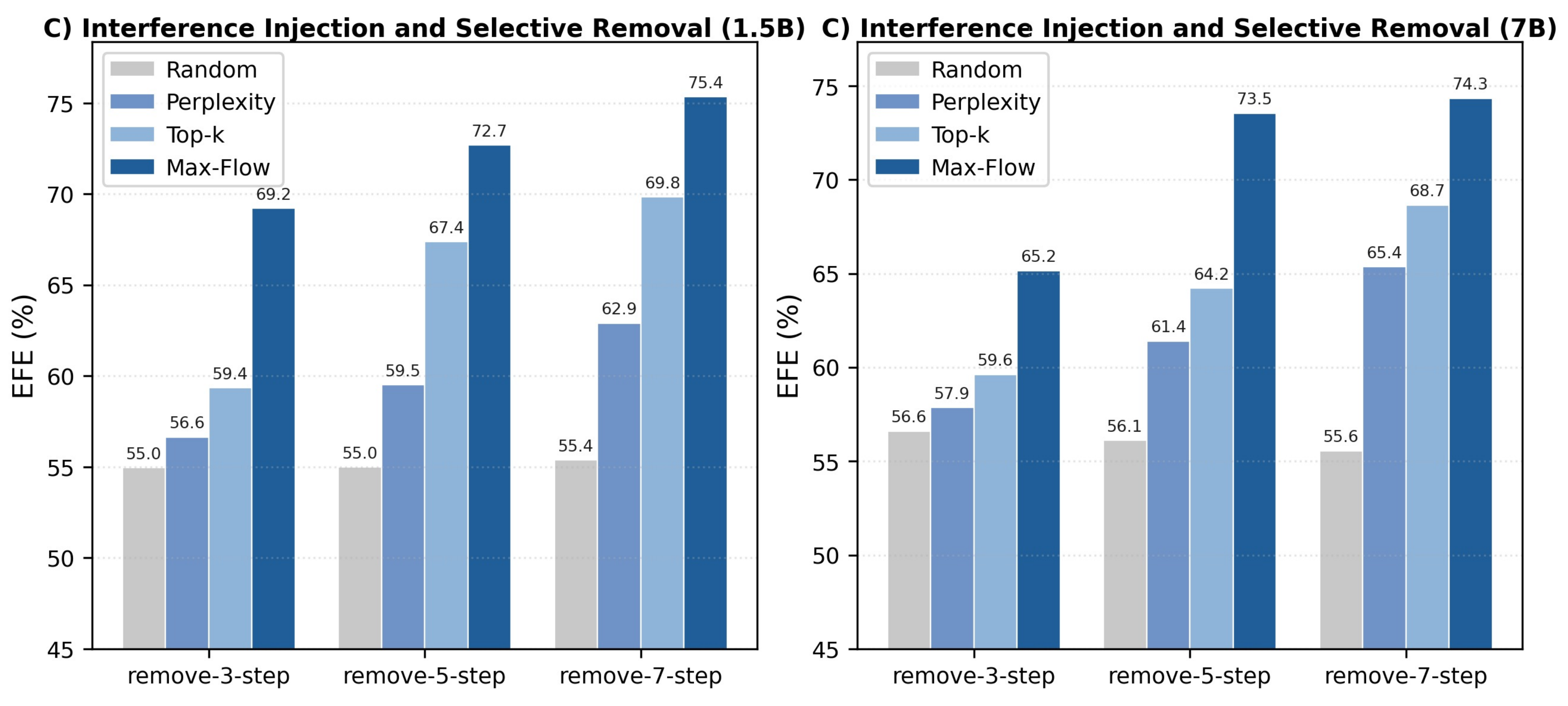
4. IISR (Interference Injection and Selective Removal)
For the IISR experiment, where we randomly inject N interference steps into an M-step reasoning process, EFE (Error Filtering Efficiency) measures the algorithm’s ability to identify and remove irrelevant steps. A value of 1.0 indicates perfect filtering.
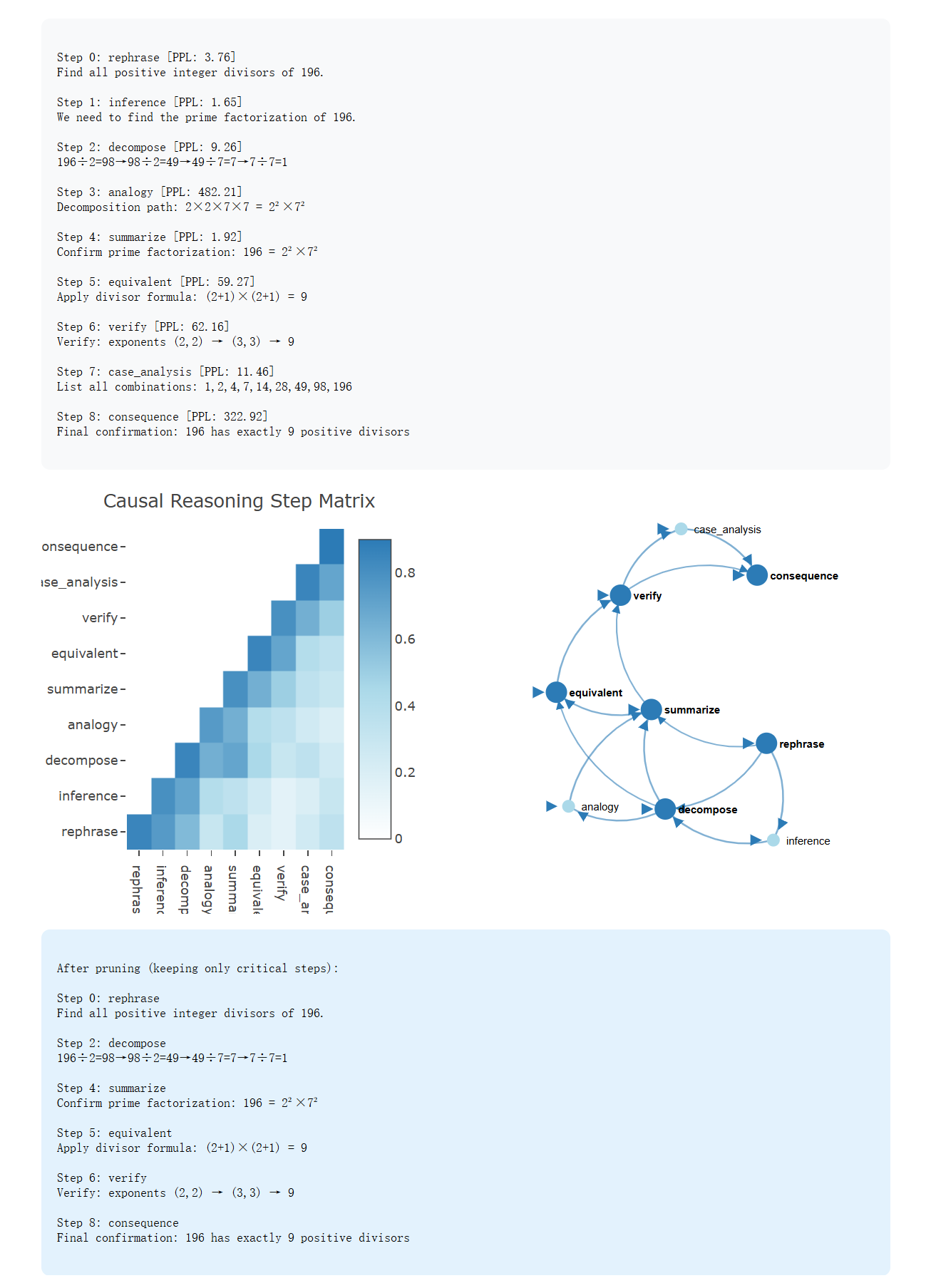
Exploration
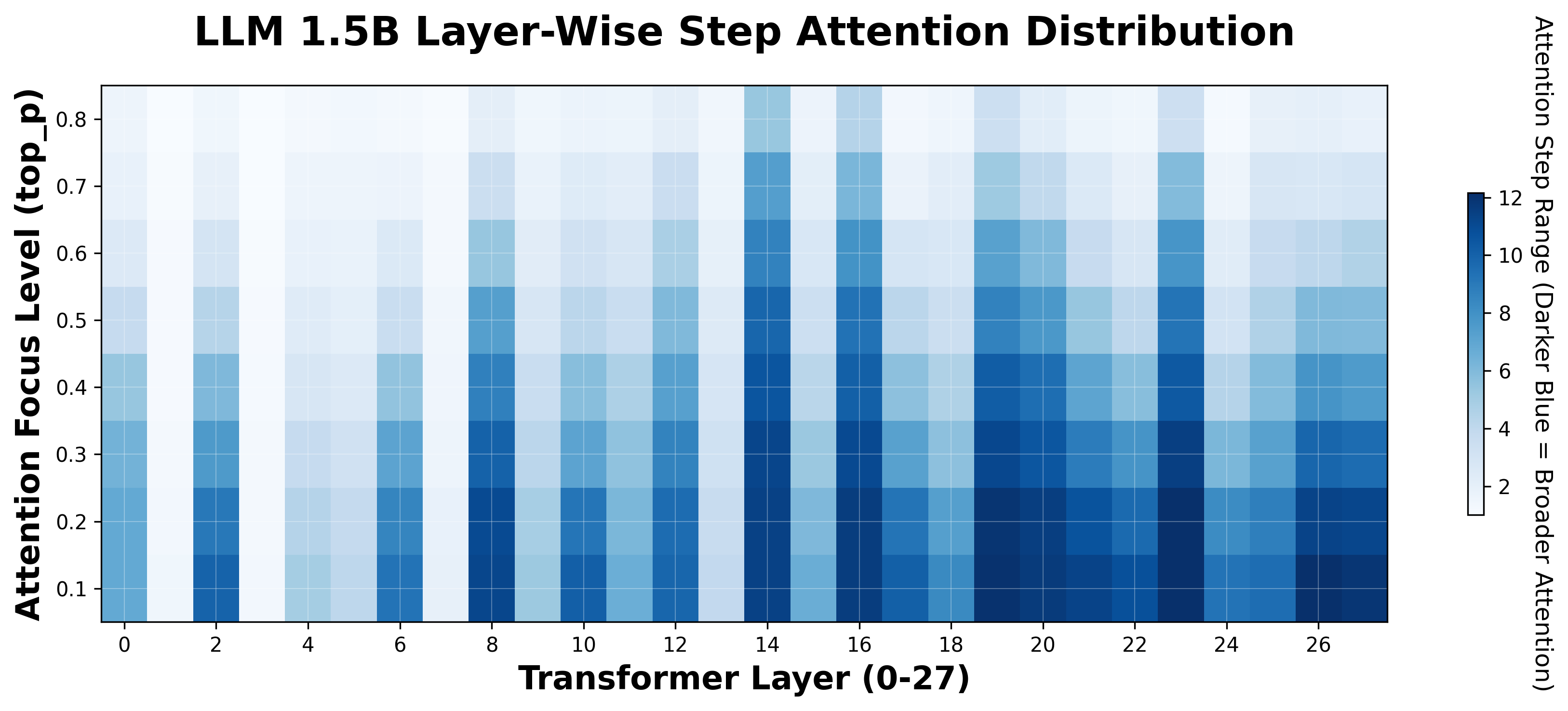
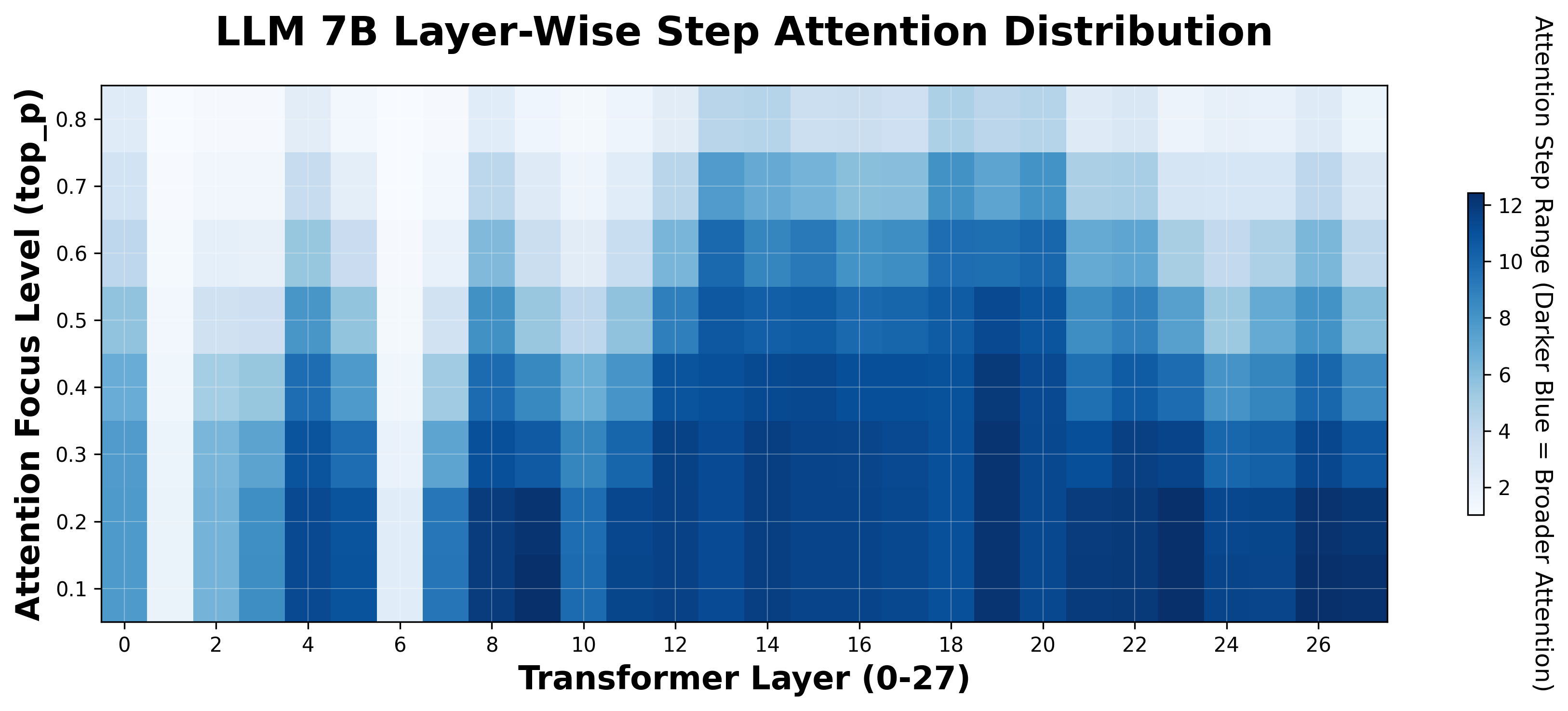
According to samples from 1.5B and 7B models with our step attention matrix thresholded at 0.1, we found that early layers (0~13) show a repeating broad-versus-local alternation, suggesting an early division of labor between aggregating multi-step context and performing local refinement. Beginning around layer 14, all subsequent layers mark a transition to a stable broad-span integration regime that more faithfully ranks step importance.
The same qualitative pattern appears in both 1.5B and 7B models: early oscillatory specialization → mid/late sustained global integration. These consistent cross-scale dynamics imply that pruning or distillation strategies could target redundant narrow-focus early layers while preserving the globally integrative mid–late region.
@inproceedings{dong2026structured,
title={Structured Reasoning for LLMs: A Unified Framework for Efficiency and Explainability},
author={Yubo Dong and Hehe Fan and Linchao Zhu and Yi Yang},
booktitle={International Conference on Machine Learning (ICML)},
year={2026}
}